|
Dr. Shivanand Sheshappanavar is a tenure-track Assistant Professor in the Department of Electrical Engineering and Computer Science (EECS) at the University of Wyoming. Dr. Sheshappanavar earned a Ph.D. in Computer and Information Sciences from the University of Delaware, where the doctoral research was conducted in the VIMS Laboratory under the supervision of Dr. Chandra Kambhamettu. In 2018, Dr. Sheshappanavar completed a Master’s degree in Computer Science at Syracuse University, New York. Prior to that, from 2012 to 2016, Dr. Sheshappanavar worked as an IT Consultant at Oracle India Private Limited. Additionally, Dr. Sheshappanavar holds a Master’s degree in Computer Science and Engineering from RVCE (2012) and a Bachelor’s degree in Computer Science and Engineering from MSRIT (2009) from Bengaluru, Karnataka, India. Dr. Sheshappanavar’s primary research interests lie in 3D computer vision and large (vision) language models, with applications spanning grocery recognition for the visually impaired, controlled-environment agriculture, and digital humanities. Recent News:
|

|
|
Email / CV / Teaching Philosophy / Google Scholar / Github / LinkedIn / PhDinUS (Facebook) / Follow @GeometricIntel / PhD Aspirants
|
|
|
|

|

|

|

|
| Assistant Professor University of Wyoming 2023 - present |
PhD, CS University of Delaware 2018 - 2023 |
MS, CS Syracuse University 2016 - 2018 |
IT Consultant Oracle 2012 - 2016 |
Research Intern Infineon 2011 - 2012 |
|
Xiao Yang (Oct 2025 - present) |
|
Michael Elgin (PhD in CS, May 2024 - present) |
|
In cluster |
|
My research interests include developing deep learning algorithms for 3D computer vision problems and creating end-to-end solution pipelines. My long-term goal is to develop a wearable assistant for the visually impaired, helping them navigate the real world. |
|
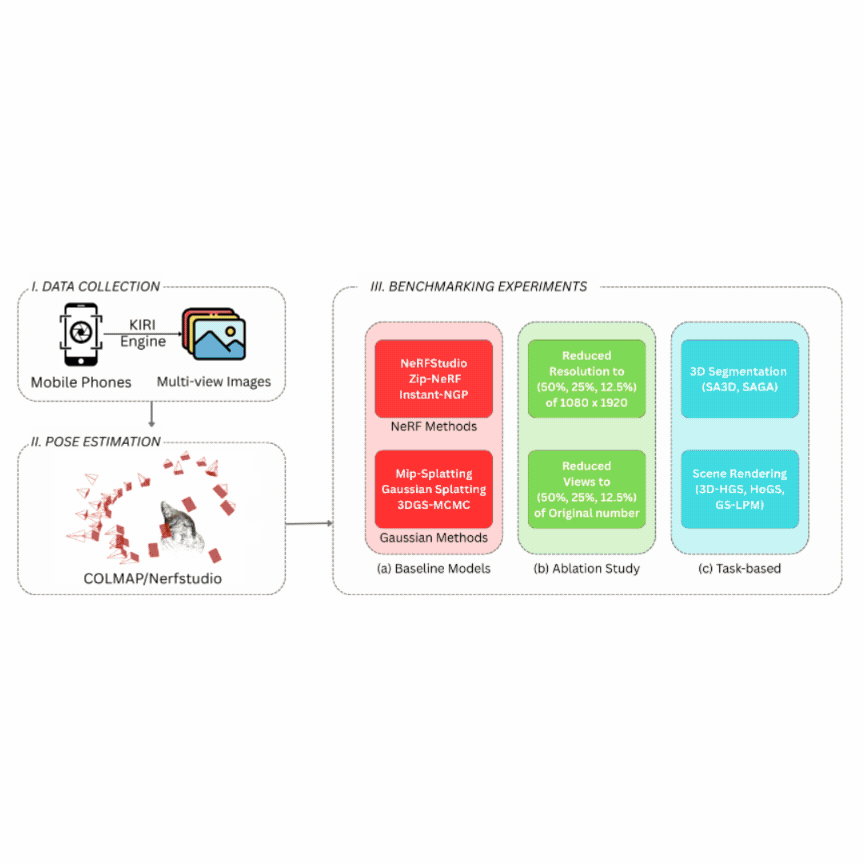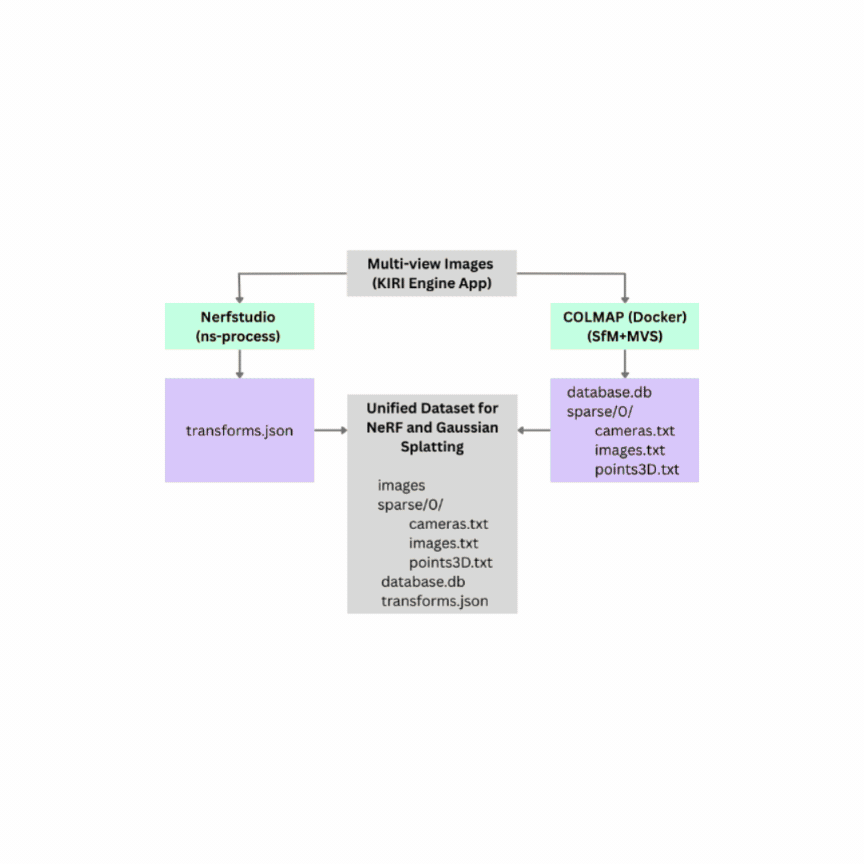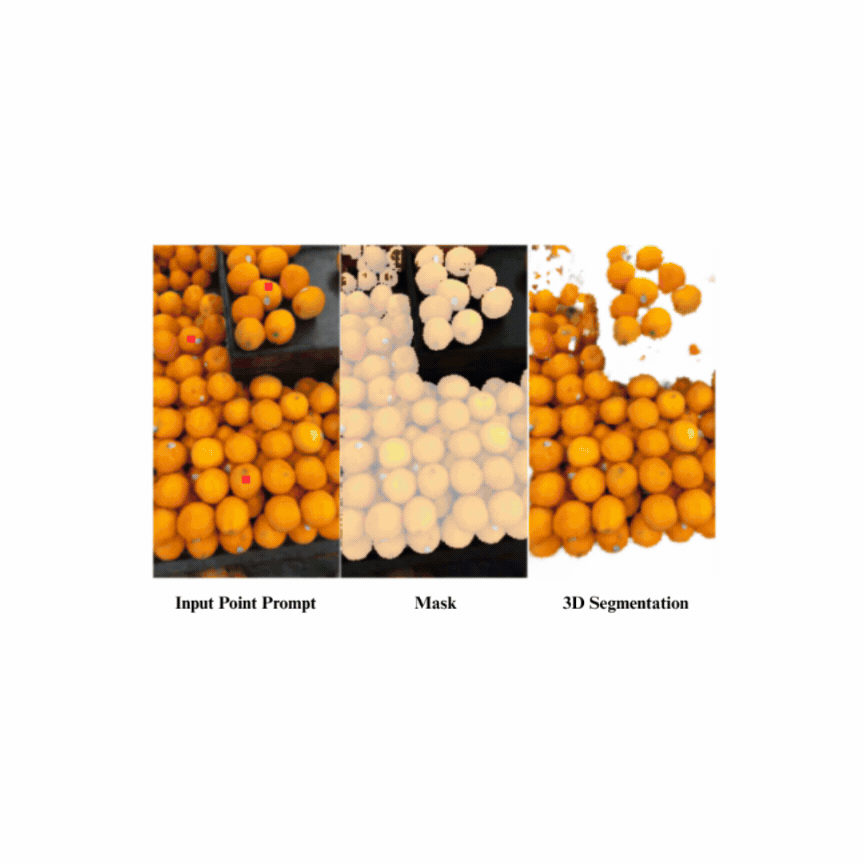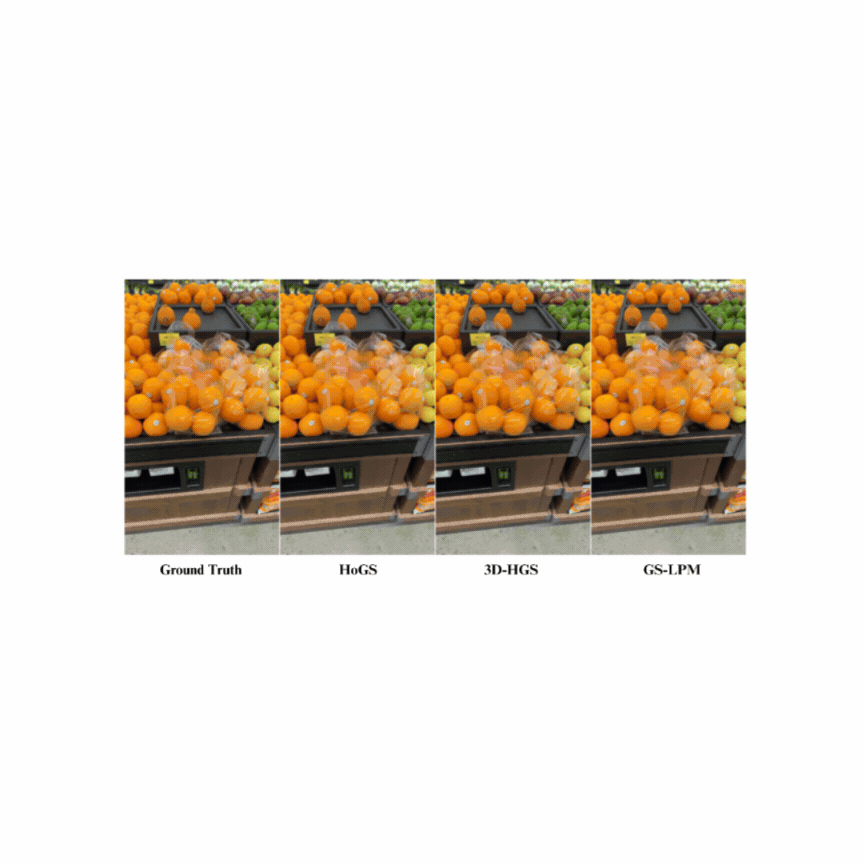
With the advent of Neural Radiance Fields (NeRFs) and 3D Gaussian Splatting (3DGS), novel view synthesis has become a central tool for 3D scene analysis. Despite progress, there remains a lack of publicly available datasets in the grocery domain, which features diverse geometry, lighting, materials, and text-rich packaging. We introduce GroceryWild500, a large-scale benchmark of 547 real-world grocery store scenes spanning fruits, vegetables, and packaged goods, organized into 74 semantic categories. Each scene is captured via mobile devices and processed into both COLMAP-style and Nerfstudio-style formats, ensuring compatibility with a wide range of reconstruction pipelines. We benchmark six state-of-the-art NeRF and 3DGS models, complemented by ablation studies on variable image resolution and views, as well as task-based experiments such as segmentation and extended Gaussian Splatting variants. Our results highlight the scale and difficulty of GroceryWild500 compared to canonical datasets. GroceryWild500 establishes a foundation for future research in reconstruction, segmentation, and multimodal scene understanding. |

|
Unsolvable Problem Detection (UPD) refers to a Large Language Model’s (LLMs) ability to recognize and refrain from responding to unsolvable or poorly posed questions, a capability that is essential for safe deployment in understanding the real world (3D scenes). Recently, UPD has gained traction in the evaluation of LLMs. However, UPD has been underexplored in the 3D domain. Although 2D-LLMs have been evaluated for UPD, similar evaluations for 3D-LLMs remain unexplored due to the novelty of the task and the lack of suitable datasets. To address this gap, we introduce the first UPD-3D benchmark constructed from the popular 3D-GRAND dataset. This benchmark comprises 11,964 scene-level samples for each of the 12 distinct UPD categories, partitioned into roughly 8,971 training and 2,993 testing instances. We establish 3D-UPD baselines by benchmarking two recent 3D-LLMs, namely MiniGPT-3D (ACM MM'24) and GreenPLM (AAAI'25). Evaluation of these 3D-LLMs directly using our test set shows critical failure modes and emphasizes the necessity of incorporating UPD capabilities into future 3D-LLMs. Our training-based evaluations of these 3D-LLMs demonstrated a significant improvement in the performance of these models in more than 50\% of the distinct UPD categories. |
|
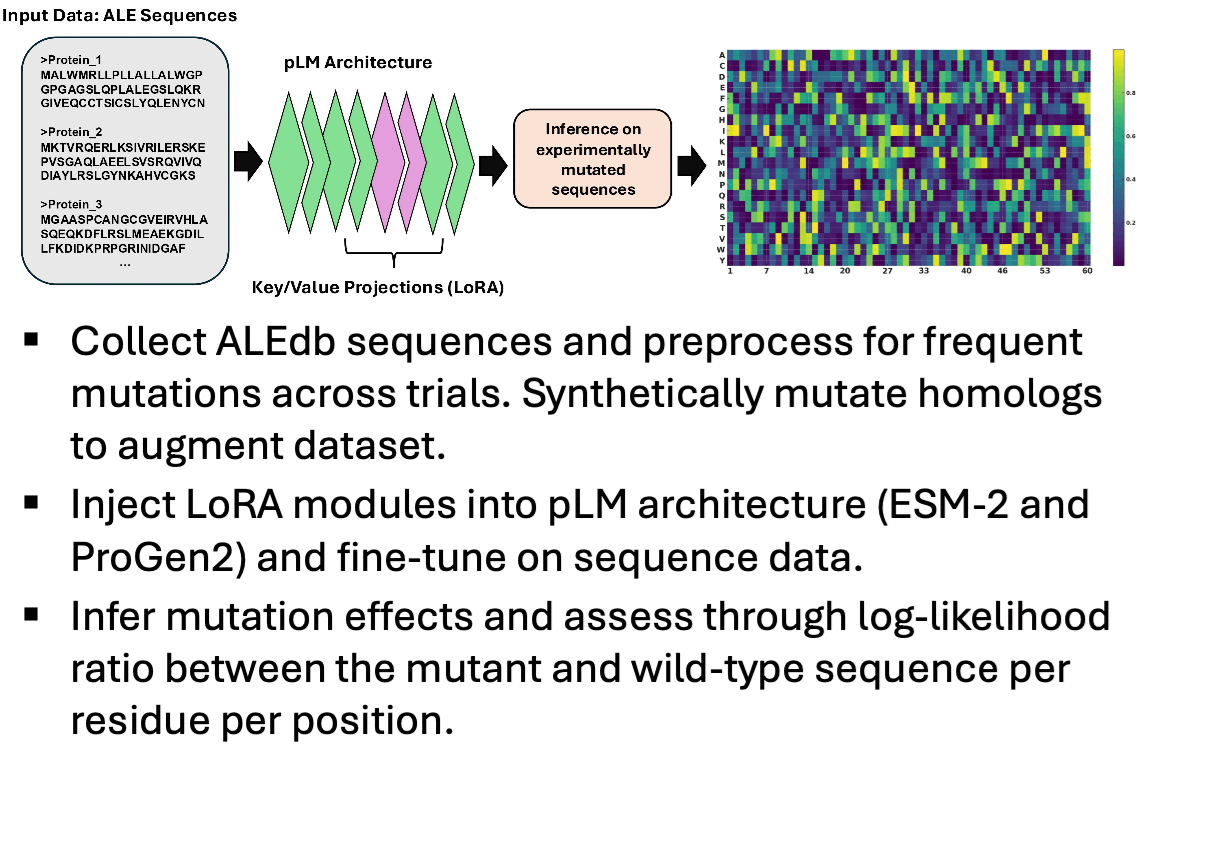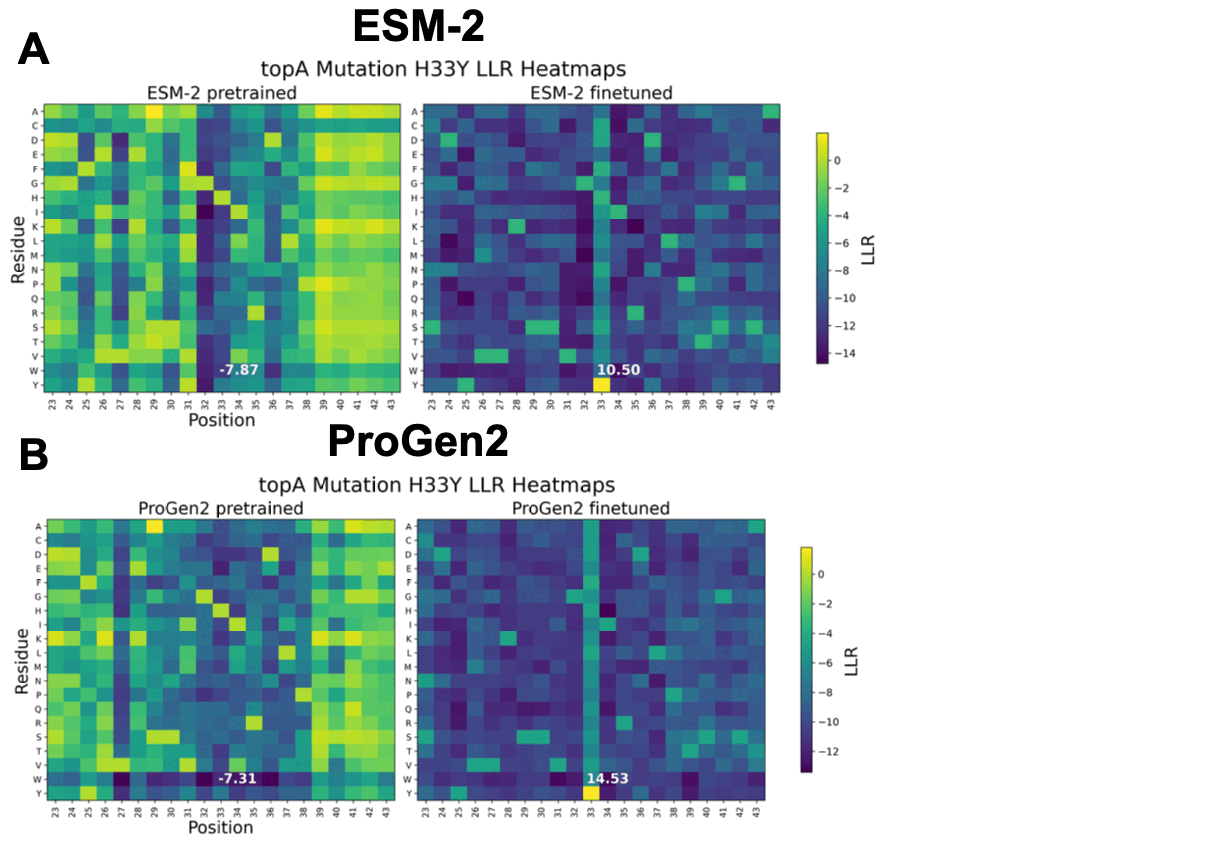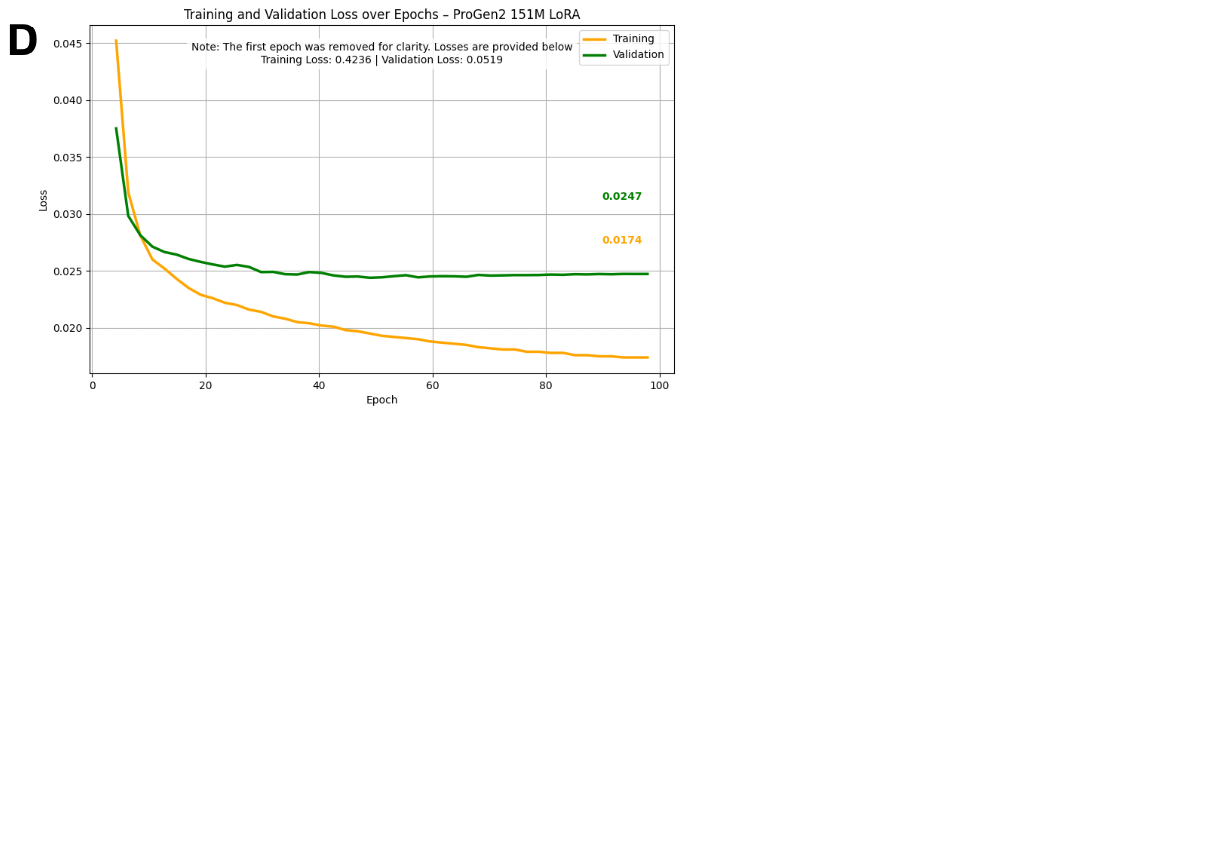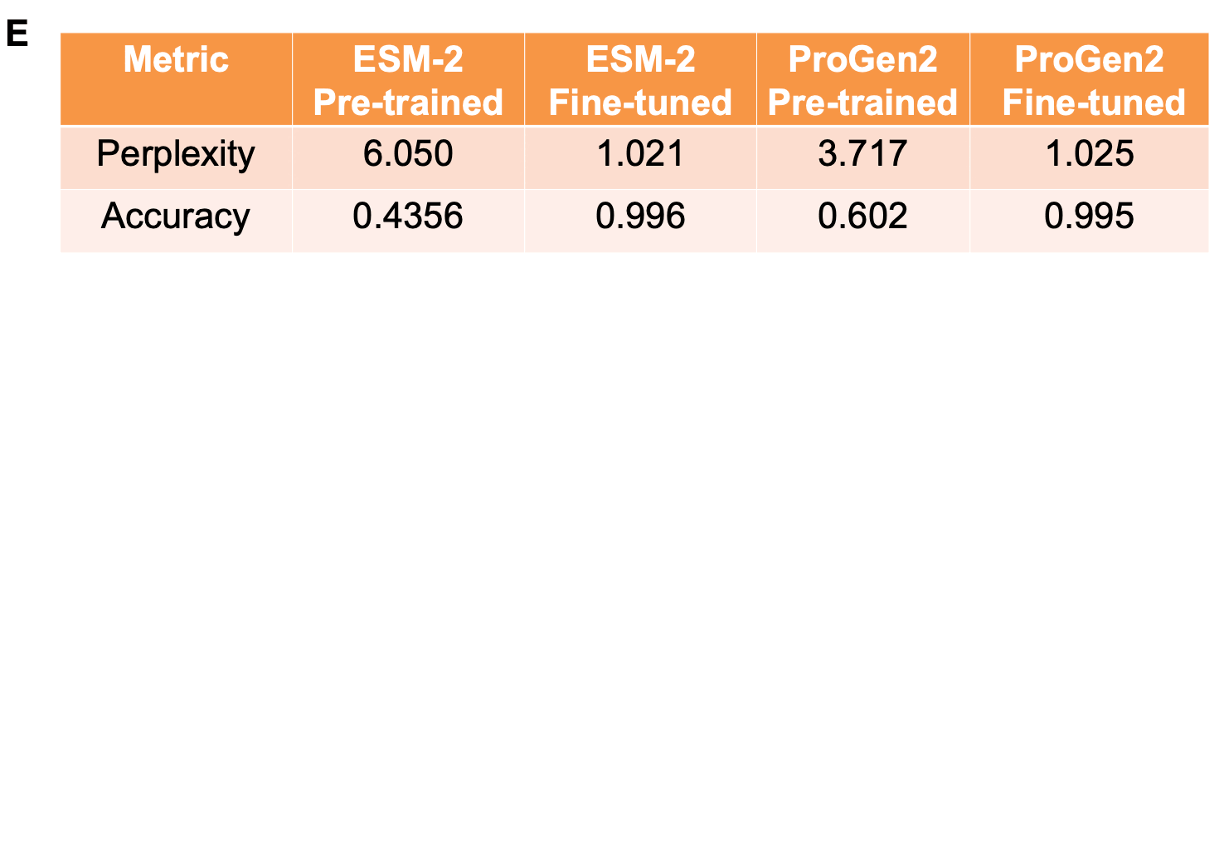
In adaptive laboratory evolution (ALE), microorganisms are subjected to a range of environmental pressures, such as temperature and radiation, in multiple experimental trials to induce naturally occurring, yet desirable, phenotypes. This approach has paved the way for innovations in protein engineering, yielding improvements in biological properties. However, ALE is constrained by its high demand for intensive resources, including the expertise of highly skilled biologists, costly equipment, and a large volume of biological samples, as well as the continuous oversight required to maintain such experimental rigor. One solution is to leverage protein language models (pLMs) to predict impactful mutations and drive evolutionary trajectories without direct human supervision. In this work, ESM-2 is fine-tuned using Low-Rank Adaptation (LoRA) on Escherichia coli data from the ALEdb database for variant effect prediction. |
|
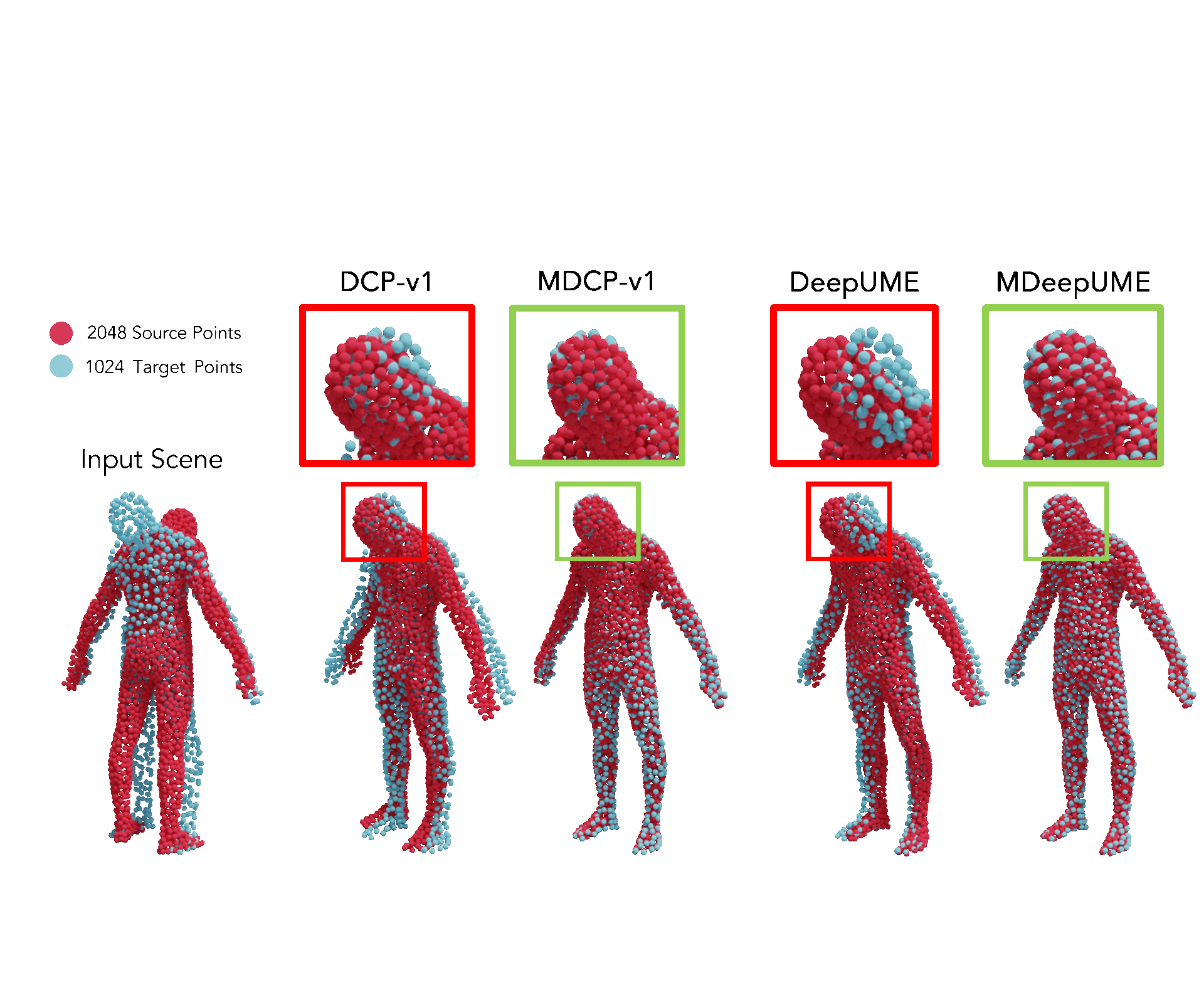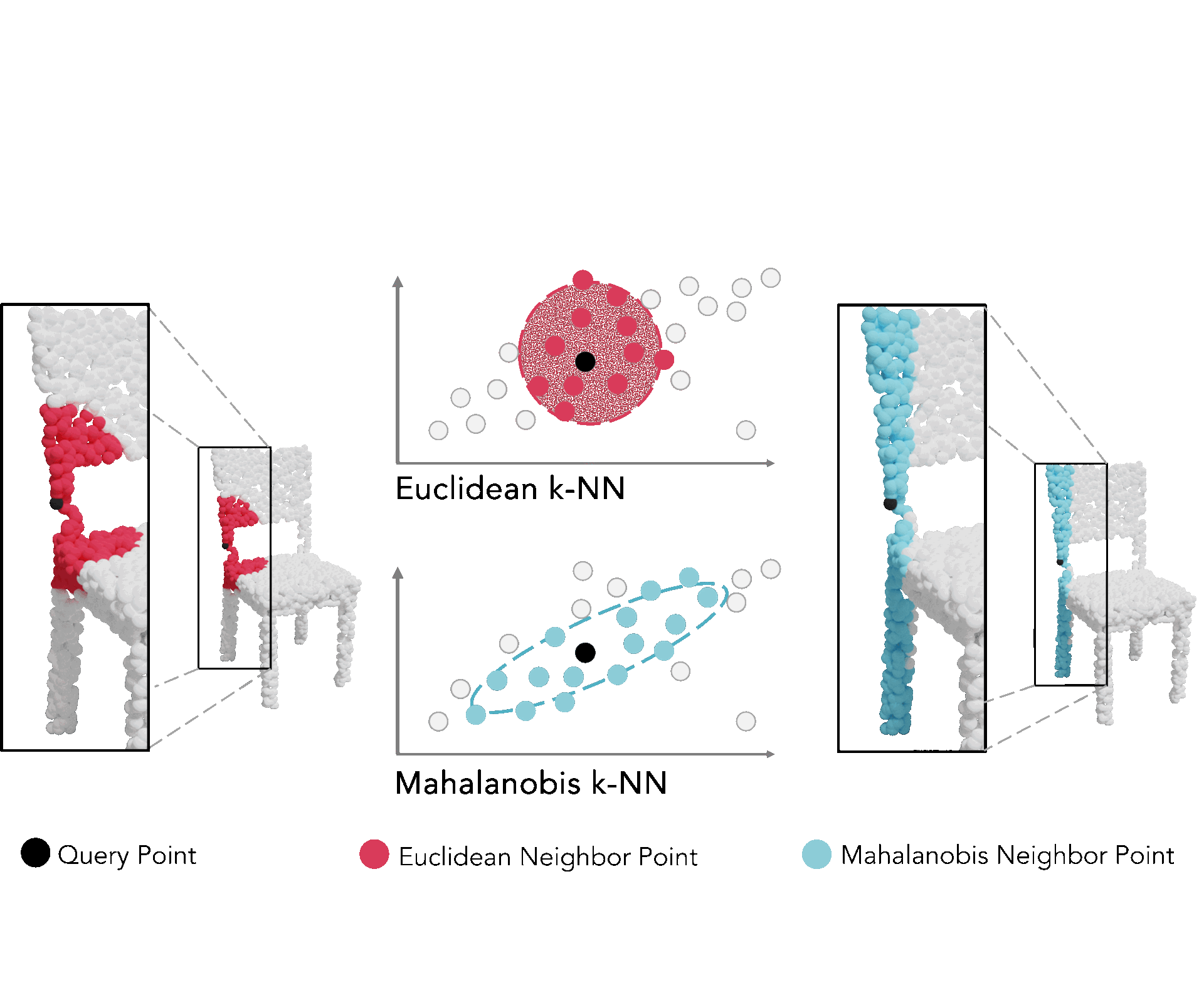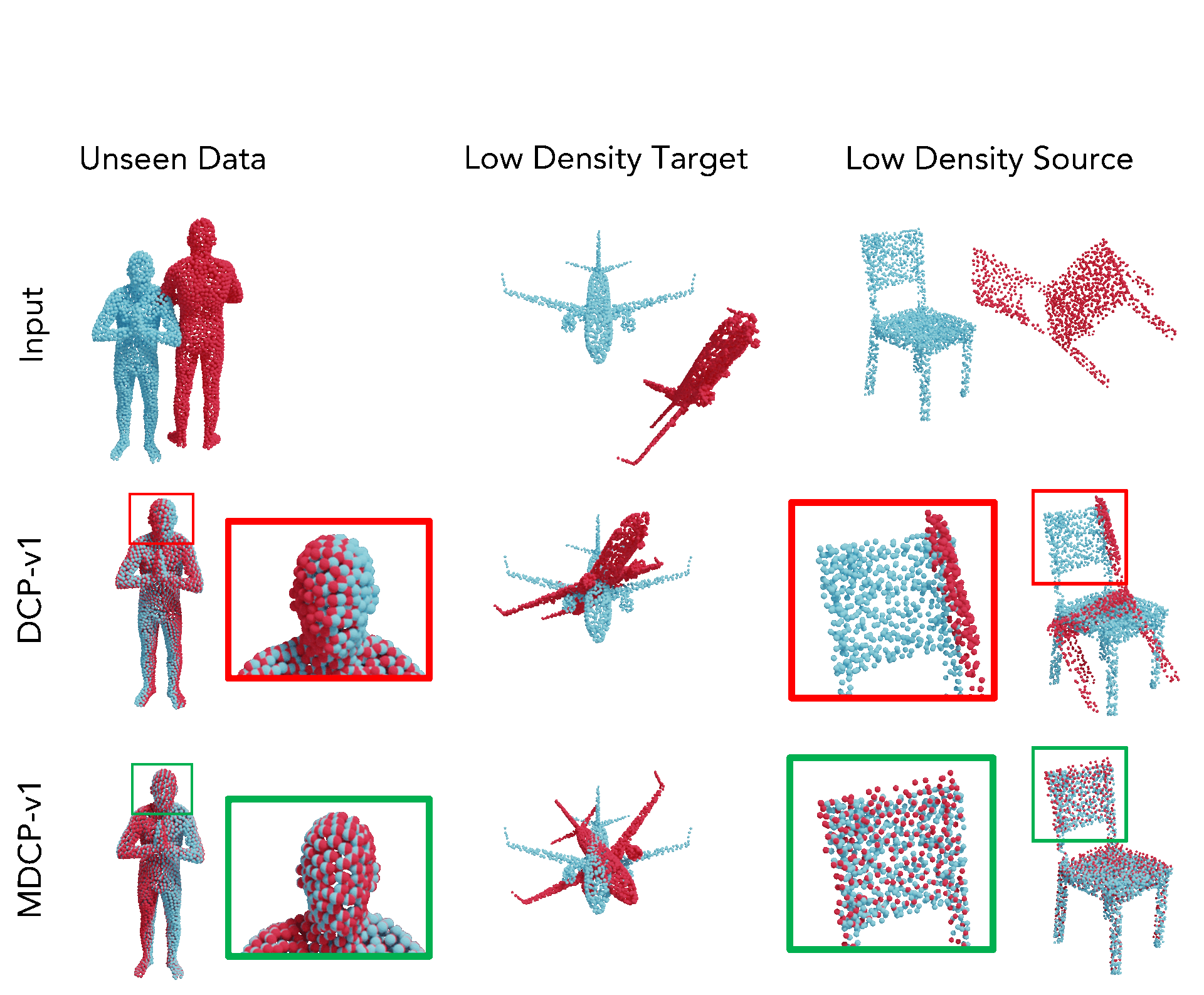
In this paper, we discuss Mahalanobis k-NN: a statistical lens designed to address the challenges of feature matching in learning-based point cloud registration when confronted with an arbitrary density of point clouds, either in the source or target point cloud. We tackle this by adopting Mahalanobis k-NN's inherent property to capture the distribution of the local neighborhood and surficial geometry. Our method can be seamlessly integrated into any local-graph-based point cloud analysis method. This paper focuses on two distinct methodologies: Deep Closest Point (DCP) and Deep Universal Manifold Embedding (DeepUME). Our extensive benchmarking on the ModelNet40 and Faust datasets highlights the efficacy of the proposed method in point cloud registration tasks. Moreover, we establish for the first time that the features acquired through point cloud registration inherently can possess discriminative capabilities. This is evident by a substantial improvement of about 20% in the average accuracy observed in the point cloud few-shot classification task benchmarked on ModelNet40 and ScanObjectNN. |

|
Due to their text-to-image synthesis feature, diffusion models have recently seen a rise in visual perception tasks, such as depth estimation. The lack of good-quality datasets makes extracting fine-grain semantic context challenging for the diffusion models. The semantic context with fewer details further worsens the process of creating effective text embeddings that will be used as input for diffusion models. This paper proposes a novel EDADepth, an Enhanced Data Augmentation method for Monocular Depth Estimation without using extra training data. We use Swin2SR, a super-resolution model, to enhance the quality of input images. We employ the BEiT pre-trained semantic segmentation model to extract better text embeddings. Furthermore, we introduce the BLIP-2 tokenizer to generate tokens from these text embeddings. The novelty of our approach is the introduction of Swin2SR, BEiT model, and BLIP-2 tokenizer in the diffusion-based pipeline for monocular depth estimation. Our model achieves state-of-the-art results (SOTA) on the d3 metric on both NYUv2 and KITTI datasets. It also achieves results comparable to those of the SOTA models in the RMSE and REL metrics. Finally, we also show improvements in the visualization of the estimated depth compared to the SOTA diffusion-based monocular depth estimation models. |

|
We introduce a large-scale grocery dataset called 3DGrocery100. It constitutes 100 classes, 10,755 RGB-D images, and 87,898 3D point cloud objects. We benchmark our dataset on six recent state-of-the-art 3D object classification models. 3DGrocery100 is the largest real-world 3D point cloud grocery dataset. |

|
With advances in deep learning model training strategies, the training of Point cloud classification methods is significantly improving. For example, PointNeXt, which adopts prominent training techniques and InvResNet layers into PointNet++, achieves over 7% improvement on the real-world ScanObjectNN dataset. However, most of these models use point coordinates features of neighborhood points mapped to higher dimensional space while ignoring the neighborhood point features computed before feeding to the network layers. In this paper, we revisit the PointNeXt model to study the usage and benefit of such neighborhood point features. |

|
We propose the use of neighbor projections along with object projections to learn finer local structural information. SimpleView++ concatenates features from orthogonal perspective projections at object and neighbor levels with encoded features from the point cloud. |

|
Different local neighborhoods on the object surface hold a different amount of geometric complexity. Applying the same data augmentation techniques at the object level is less effective in augmenting local neighborhoods with complex structures. This paper presents PatchAugment, a data augmentation framework to apply different augmentation techniques to the local neighborhoods. |
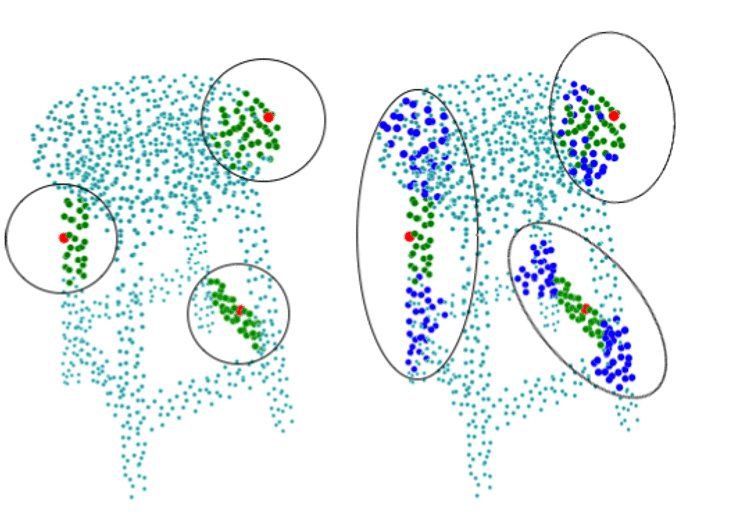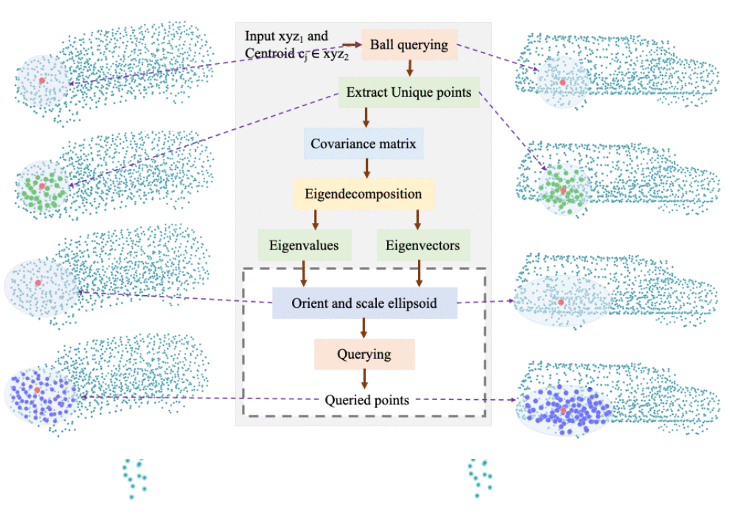
|
PointNet++ model uses ball querying for local geometry capture in its set abstraction layers. Several models based on single scale grouping of PointNet++ continue to use ball querying with a fixed-radius ball. However, ball lacks orientation and is ineffective in capturing complex or varying geometry proportions from different local neighborhoods on the object surface. We propose a novel technique of dynamically oriented and scaled ellipsoid based on unique local information to capture the local geometry better. We also propose ReducedPointNet++, a single set abstraction based single scale grouping model. |

|
In this paper, inspired by dilated convolutions for images, we proffer dilated convolutions for meshes. Our Dilated Mesh Convolution (DMC) unit inflates the kernels' receptive field without increasing the number of learnable parameters. We also propose a Stacked Dilated Mesh Convolution (SDMC) block by stacking DMC units. We accommodated SDMC in MeshNet to classify 3D meshes. |

|
MeshNet is a pioneer in this direction. In this paper, we propose a novel neural network that is substantially deeper than its MeshNet predecessor. This increase in depth is achieved through our specialized convolution and pooling blocks that operate on mesh faces. Our network named MeshNet++ learns local structures at multiple scales and is also robust to shortcomings of mesh decimation. We evaluated it for the shape classification task on various data sets, and results significantly higher than state-of-the-art were observed. |
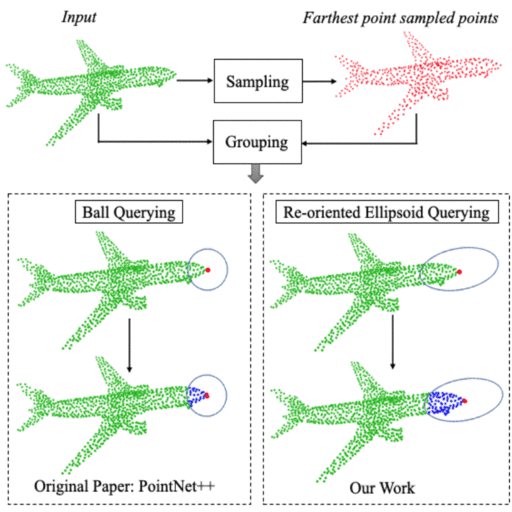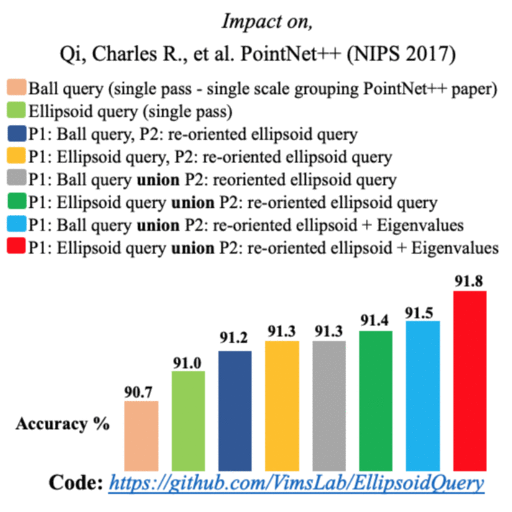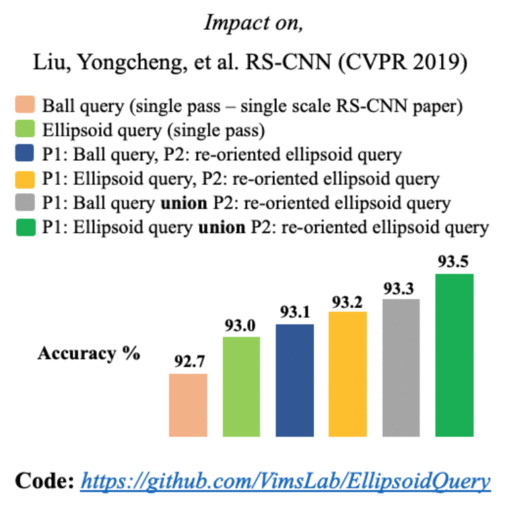
|
Few of the recent deep learning models for 3D point sets classification are dependent on how well the model captures the local geometric structures. PointNet++ model was able to extract the local region features from points by ball querying the local neighborhoods. However, ball querying is less effective in capturing local neighborhoods of high curvature surfaces or regions. In this paper, we demonstrate improvement in the 3D classification results by using ellipsoid querying around centroids, capturing more points in the local neighborhood. We extend the ellipsoid querying technique by orienting it in the direction of principal axes of the local neighborhood for better capture of the local geometry. |
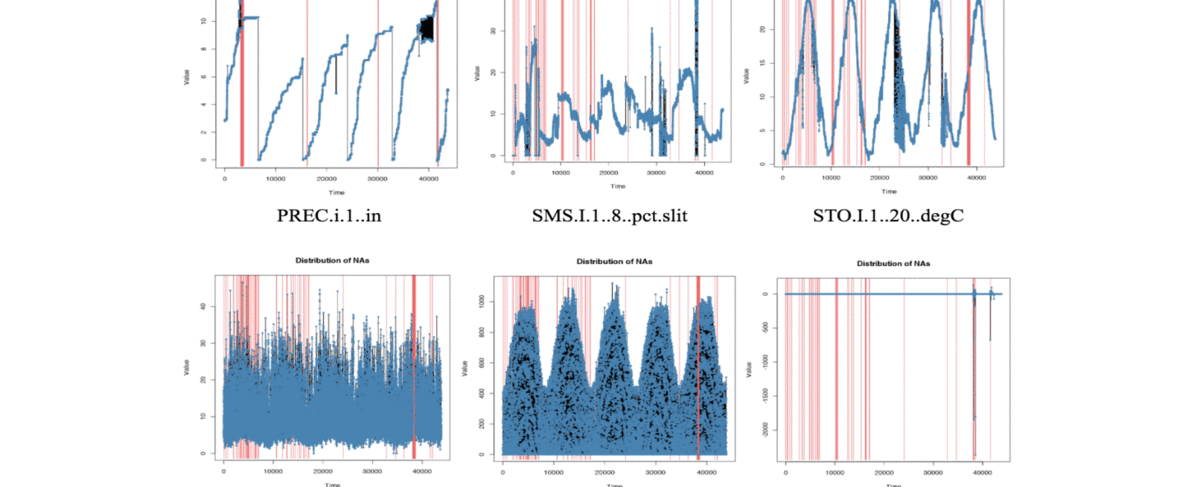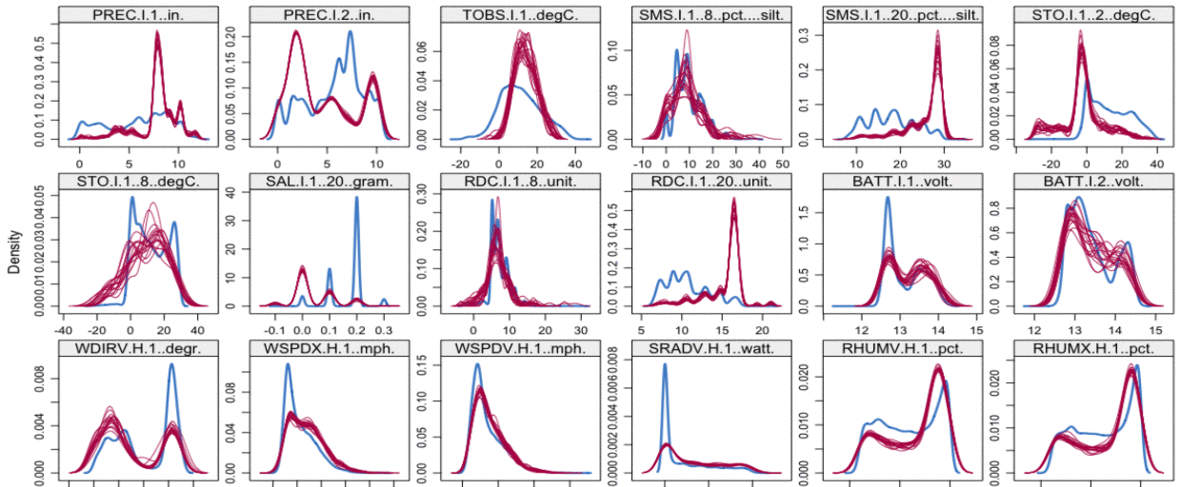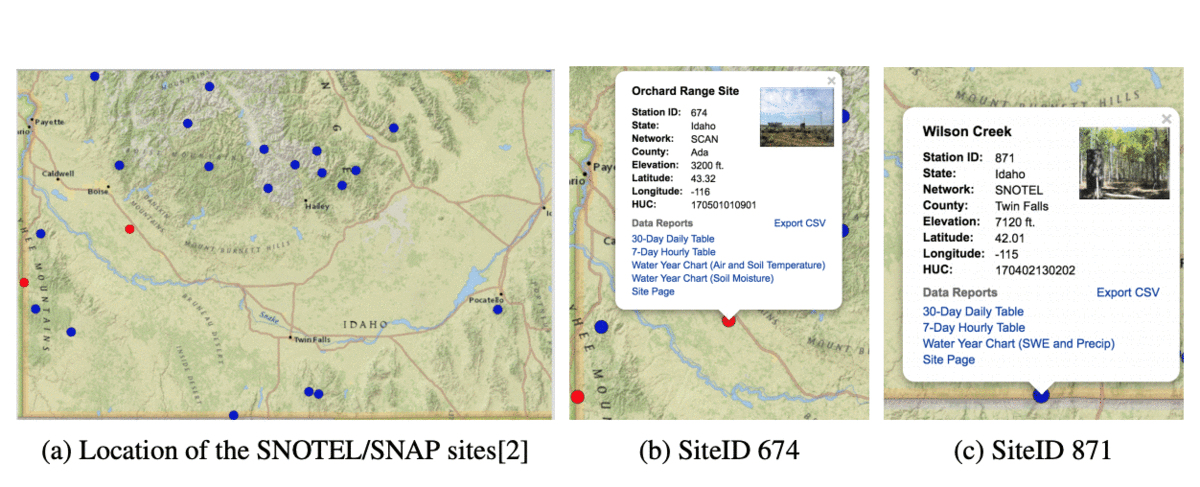
|
Soil moisture content is an important variable that has a considerable impact on agricultural processes and practical weather-related concerns such as flooding and drought. We address the problem of predicting soil moisture by applying recurrent neural networks that use Long Short-Term Memory (LSTM) models. The success of our approach is evaluated using a dataset obtained from ground-based sensor infrastructure networks. Feature reduction using a mutual information approach is shown to be more effective than feature extraction using principal component analysis. |
|
I have been the Instructor for the following courses at the University of Wyoming:
|
